
Windwos MiniConda、Windows Wsl、Linux 部署 Vicuna 都可借鉴该文档!
一、安装 WSL
Windows 安装 WSL
二、安装 Git
# yum install -y git [如果有Git可以忽略]
# git --version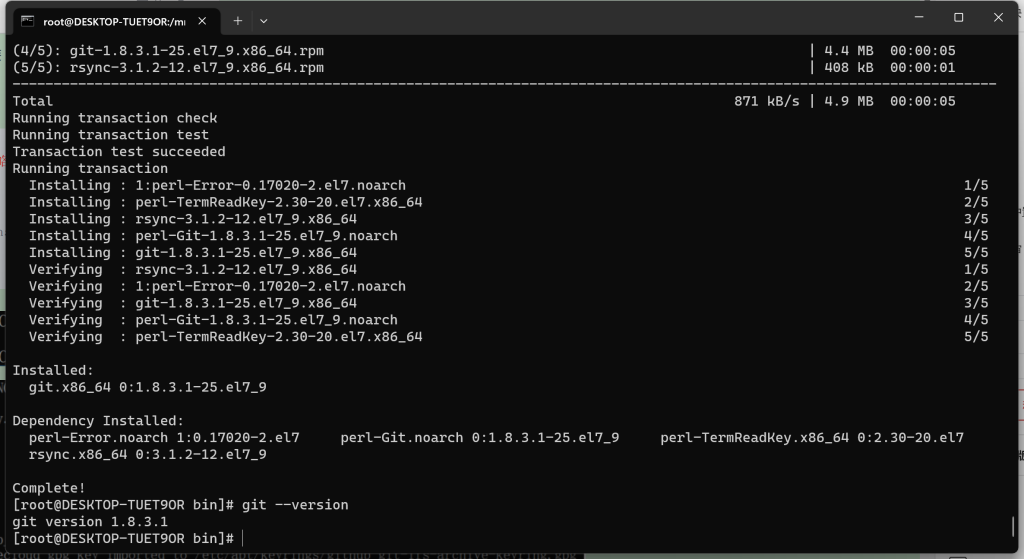
若需要使用 Git 下载权重的伙伴,可以按照教程安装 git-lfs 先,否则大文件下载将会失败。
Linux 安装 git-lfs
三、安装 Conda
Linux 安装 MiniConda
四、安装 Nvidia、CUDA、cuDNN
WSL 安装的 Oracle Linux 默认有 Nvidia 驱动,执行 # nvidia-smi 可查看信息。
发现在安装 FastChat 时,会自动安装 CUDA 环境。【请忽略,往下执行便可】
注意:如果你是使用的 Windows MiniConda 部署的话,则需要参考以下的教程,在 Windows 上安装 CUDA、cuDNN,否则无法使用 GPU 的启动。
Windows 安装 CUDA、cuDNN
五、创建目录
# cd /mnt/d/Desktop/
# mkdir Vicuna
# cd Vicuna
# ls
六、获取 LLaMA 权重文件
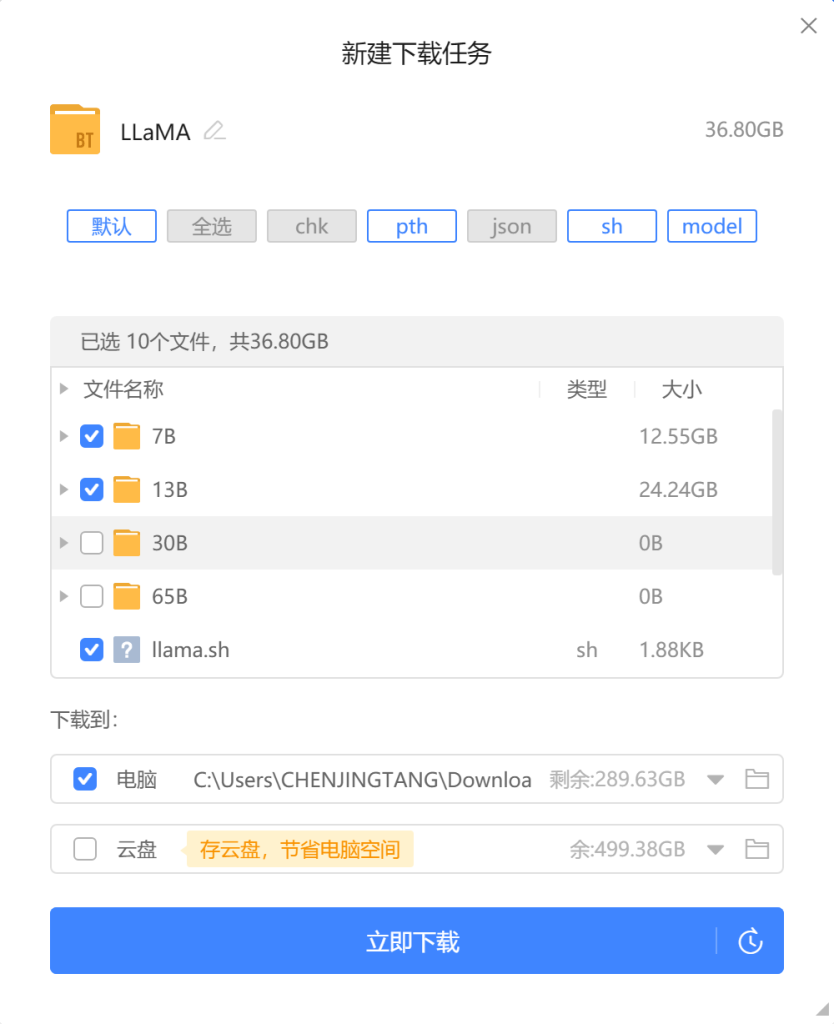
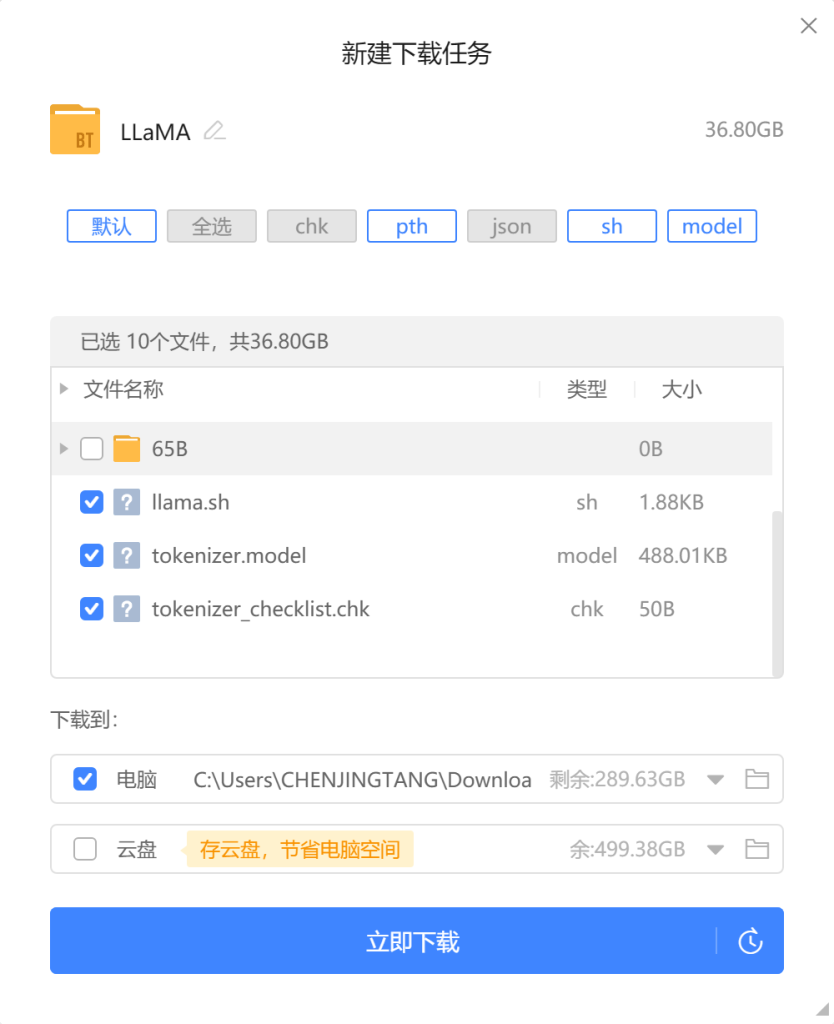
1、磁力链接下载
【本文使用方法】
磁力链接:magnet:?xt=urn:btih:b8287ebfa04f879b048d4d4404108cf3e8014352&dn=LLaMA
2、指令下载
【验证可用,本文不采纳,使用磁力下载的请忽略】
注意:该指令不能时刻查看下载进度,比较无奈。不过好在该指令中断后,重新执行时,是延续下载,非重新下载。
# pip install pyllama -U
# python -m llama.download --model_size 7B
# python -m llama.download --model_size 13B七、获取 Delta 权重文件
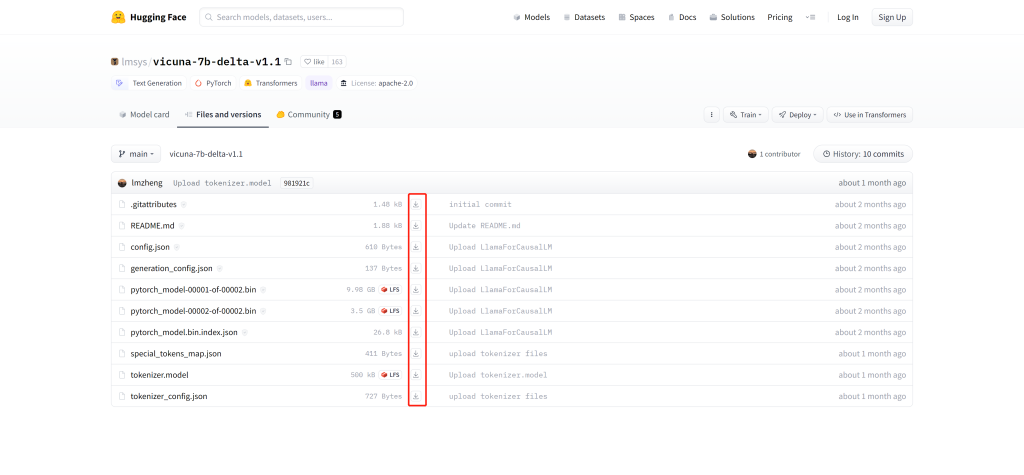
1、浏览器下载
【本文使用方法】
访问 https://huggingface.co/lmsys/vicuna-7b-delta-v1.1/tree/main 获取 Vicuna Delta 7B
访问 https://huggingface.co/lmsys/vicuna-13b-delta-v1.1/tree/main 获取 Vicuna Delta 13B
2、Git 下载
# git lfs clone https://huggingface.co/lmsys/vicuna-7b-delta-v1.1
# git lfs clone https://huggingface.co/lmsys/vicuna-13b-delta-v1.1八、安装、执行步骤
1、查看权重文件

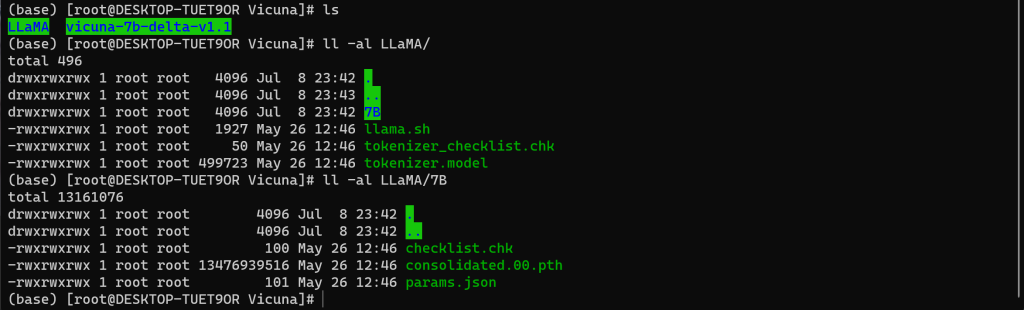
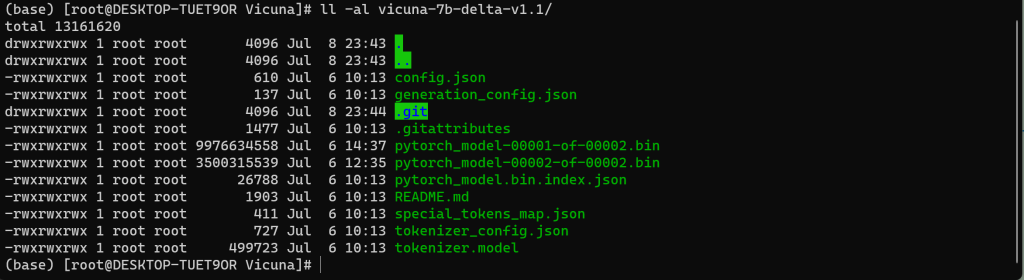
九、安装环境
1、创建虚拟环境
# conda create -n vicuna python==3.10
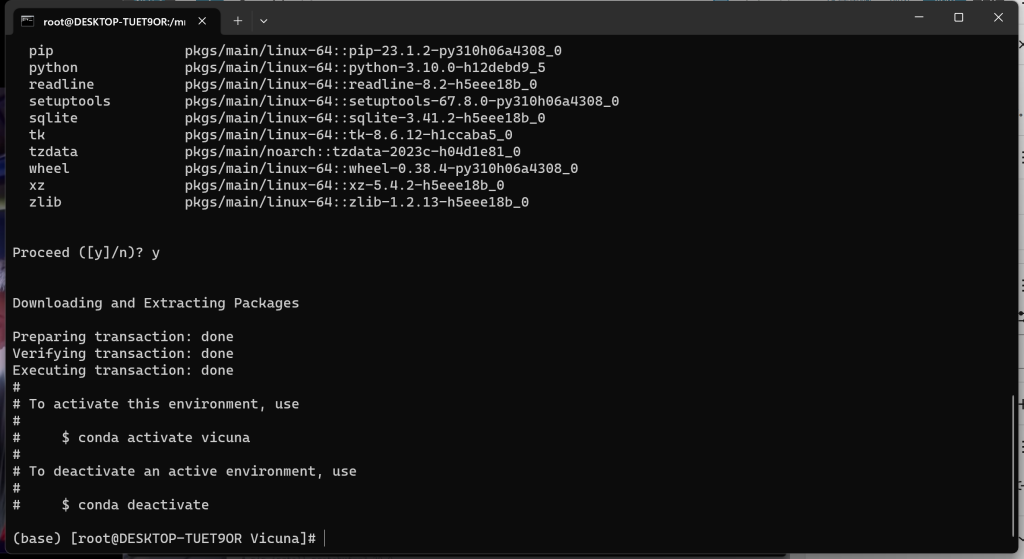
2、激活虚拟环境
# conda activate vicuna
3、安装 FastChat
# pip install fschat
# git clone https://github.com/lm-sys/FastChat
# cd FastChat
# git tag
# git checkout v0.2.3
# pip install e .
# cd ../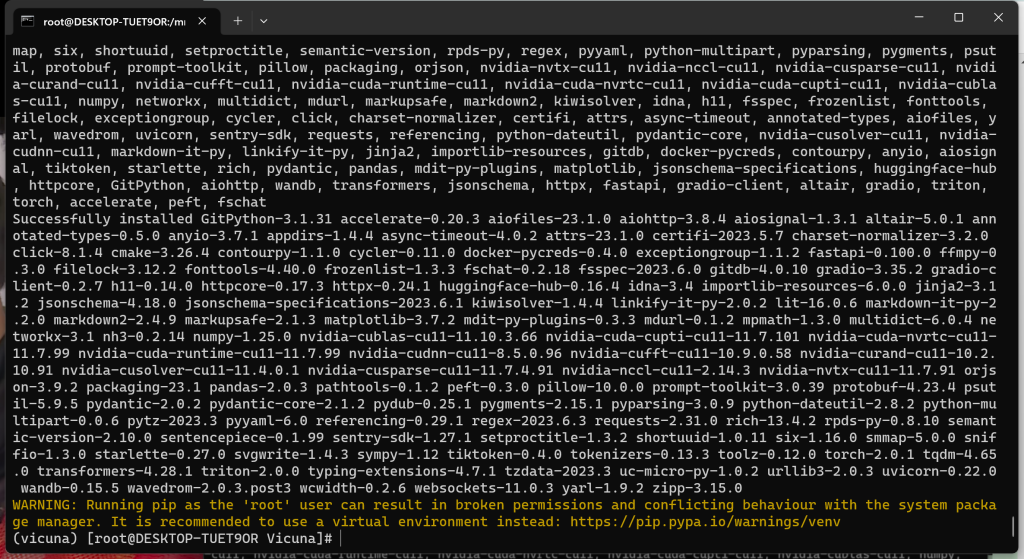
4、安装 Protobuf
# pip install protobuf==3.20.0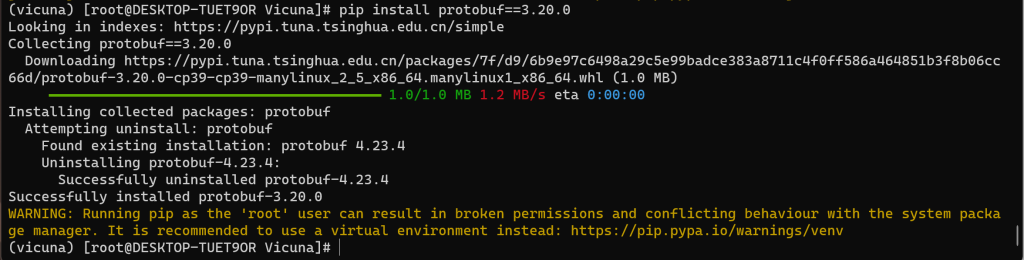
5、安装 Transformers
# git clone https://github.com/huggingface/transformers.git
# cd transformers
# pip uninstall transformers 【卸载旧的环境包,不卸载的话不能被替换成更新的版本】
# python setup.py install
# cd ../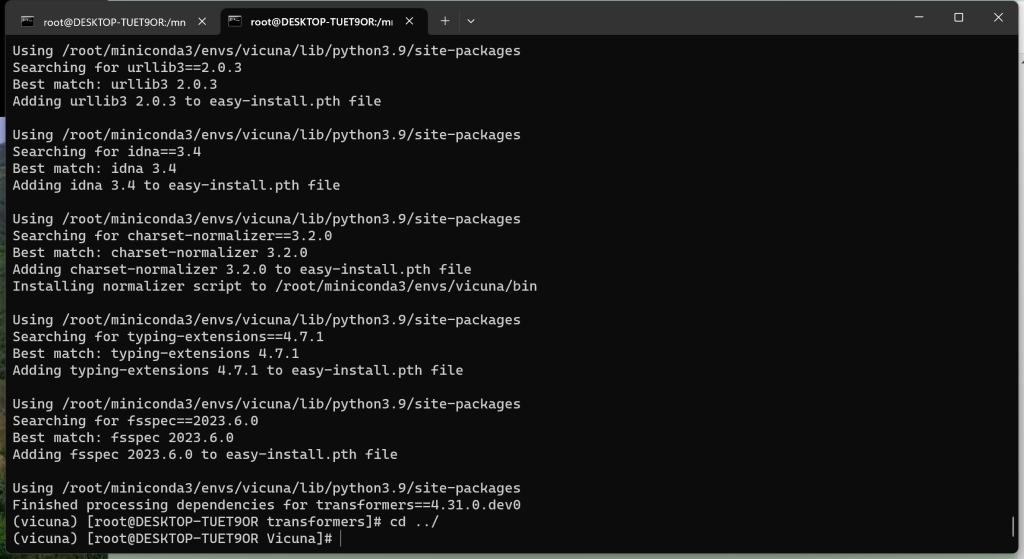
十、转换 LLaMa 模型
如果你不想手动转换 LLaMa 模型,可以直接通过 Git 下载转换好的文件,直接使用
注意:本文未做验证,有兴趣的可以试试
如果使用该方式,则 【十、转换 LLaMa 模型】其他内容可以不用看了,但若后面有关于环境错误的内容,可以检索本文是否有解决方法
# git lfs clone https://huggingface.co/huggyllama/llama-7b
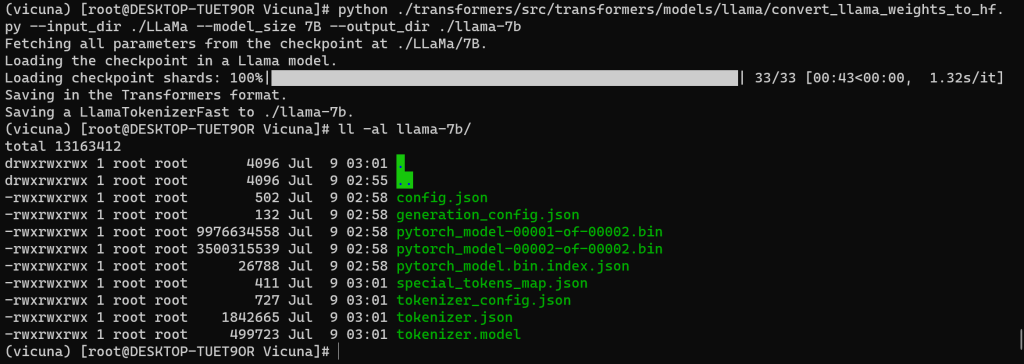
# git lfs clone https://huggingface.co/huggyllama/llama-13b在转换前,需要找到指令执行需要的脚本文件 convert_llama_weights_to_hf.py !!!
脚本地址:./transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py# python ./transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir ./LLaMa --model_size 7B --output_dir ./llama-7b参数解释
| –input_dir * | LLaMA权重文件的路径 |
| –model_size * | 7B 或 13B |
| –output_dir * | 转换成功后的保存路径 |
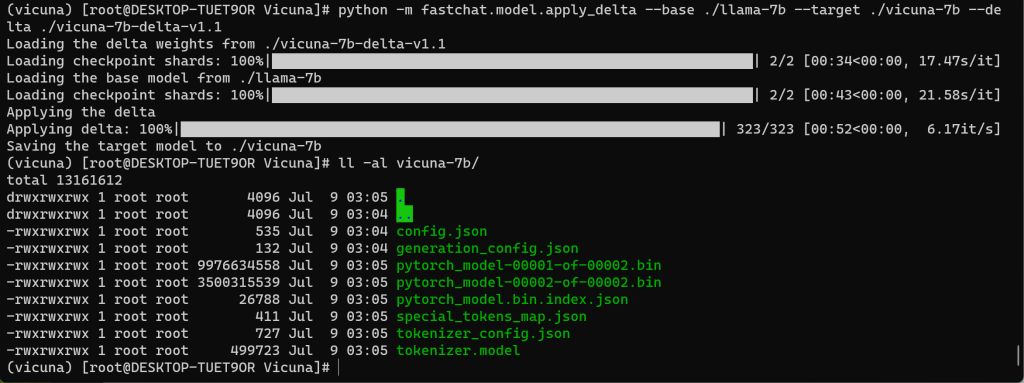
十一、合并 LLaMa 生成 Vicuna 模型
# python -m fastchat.model.apply_delta --base ./llama-7b --target ./vicuna-7b --delta ./vicuna-7b-delta-v1.1参数解释
| –base * | 转换 LLaMA 模型后的路径 |
| –target * | 合并生成后的保存路径 |
| –delta * | 7B 使用 vicuna-7b-delta-v1.1、13B 使用 vicuna-13b-delta-v1.1 |
如果在执行过程中,出现 python killed 问题,可以查阅以下文章中遇到问题后的处理方案:
Windows · Linux 部署 MiniGPT-4
十二、启动与演示
1、命令行模式
# python -m fastchat.serve.cli --model-path ./vicuna-7b 【默认GPU启动】
或
# python -m fastchat.serve.cli --model-path ./vicuna-7b --device cpu 【设置CPU启动】参数解释
| –model-path * | 合并 LLaMA 生成 Vicuna 模型的路径 |
| –device cpu | CPU 运行 |
| –load-8bit | 量化,把32位的浮点参数压缩成8位,速度会变快,运存或显存会变小,但智力下降 如:python -m fastchat.serve.cli –model-path ./vicuna-7b –load-8bit |
启动与演示效果
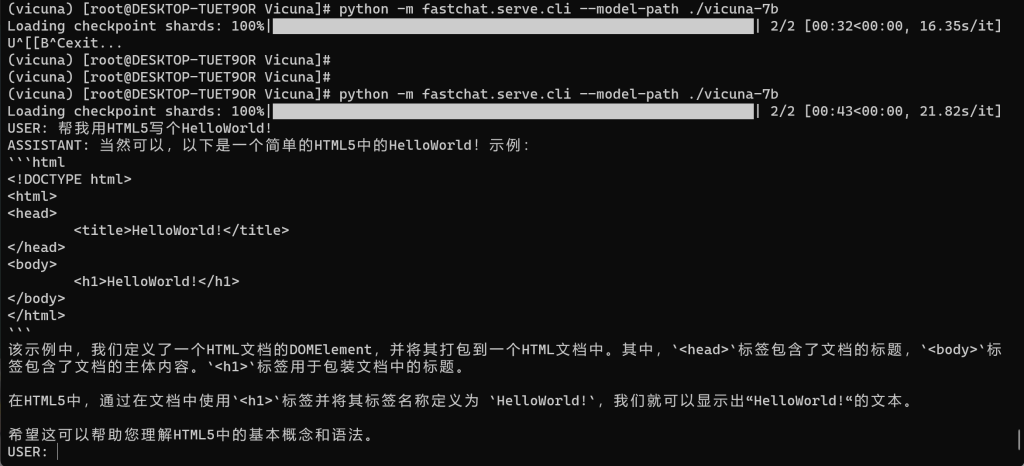
2、Api 模式
命令行窗口启动 【需三个窗口执行指令】
# python -m fastchat.serve.controller
# python -m fastchat.serve.model_worker --model-name vicuna-7b --model-path ./vicuna-7b
# python -m fastchat.serve.openai_api_server --host localhost --port 8000
后台启动
# nohup python -m fastchat.serve.controller > controller.log 2>&1 &
# nohup python -m fastchat.serve.model_worker --model-name vicuna-7b --model-path ./vicuna-7b > model_worker.log 2>&1 &
# nohup python -m fastchat.serve.openai_api_server --host localhost --port 8000 > openai_api_server.log 2>&1 &窗口一 | 指令一:

窗口二 | 指令二:
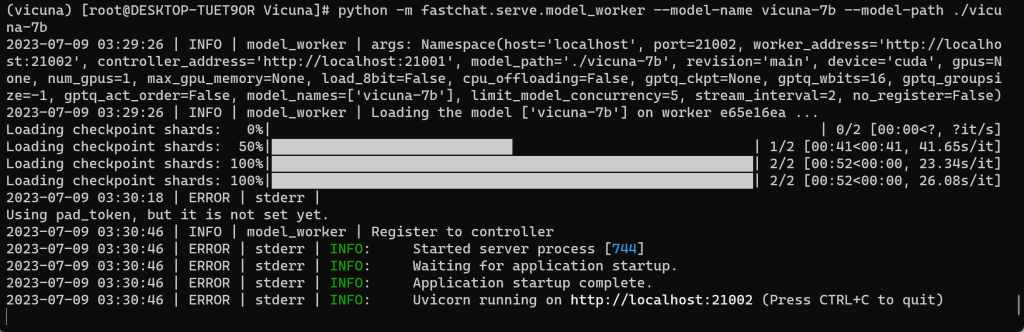
窗口三 | 指令三:
异常处理:
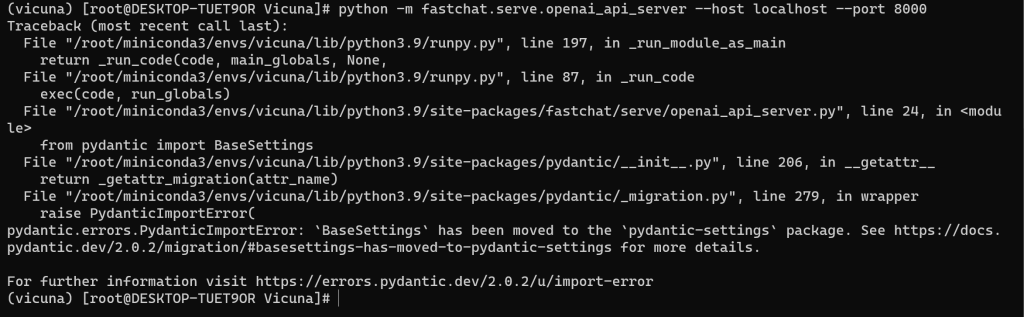
pydantic.errors.PydanticImportError: `BaseSettings` has been moved to the `pydantic-settings` package. See https://docs.pydantic.dev/2.0.2/migration/#basesettings-has-moved-to-pydantic-settings for more details.
For further information visit https://errors.pydantic.dev/2.0.2/u/import-error
# pip uninstall pydantic_core
# pip uninstall pydantic
# pip install pydantic=1.10.11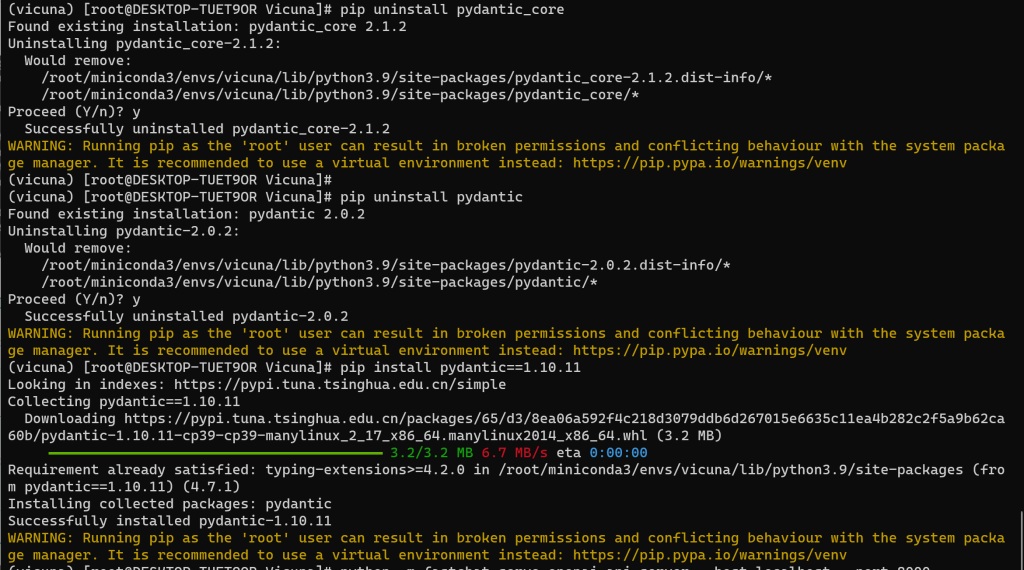
备注:该问题的处理方案,是对比了正常启动 Vicuna 的环境,发现 pydantic 环境的版本不一致,且高版本的会附带其他的环境,所以对此将不正常的环境卸载,改成正常环境的版本号,就正常了。

在线 Api 文档 | FastChat – openai.api.md 测试案例
演示效果:
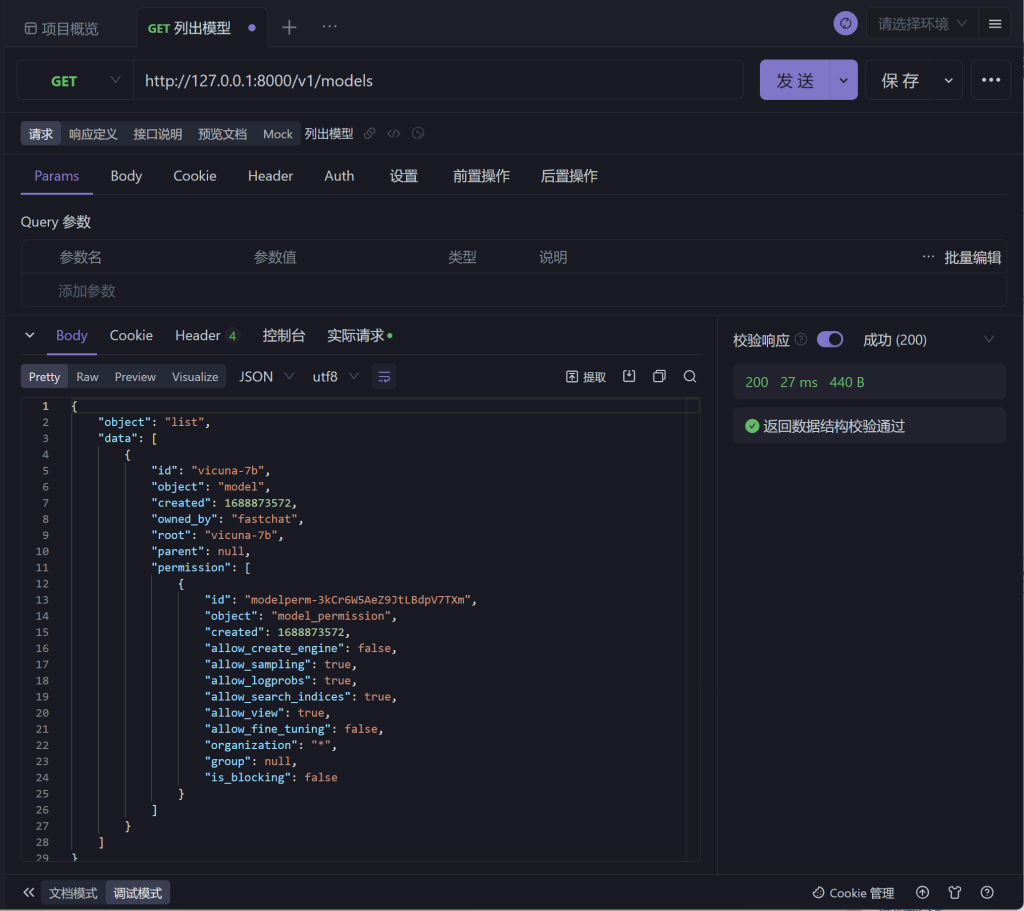
使用 Apifox 与 Java HttpUtil 请求 Chat Completions、Text Completions 均会异常 400 !!! 不清楚是 Http TimeOut 还是什么问题,此问题滞留先,不做处理!
若是有处理的博主,可以的话,希望联系我完善我的博客内容,谢谢。
3、Web 模式
命令行窗口启动 【需三个窗口执行指令】
# python -m fastchat.serve.controller
# python -m fastchat.serve.model_worker --model-name 'vicuna-7b' --model-path ./vicuna-7b
# python -m fastchat.serve.gradio_web_server --host localhost --port 8000
后台启动
# nohup python -m fastchat.serve.controller > controller.log 2>&1 &
# nohup python -m fastchat.serve.model_worker --model-name 'vicuna-7b' --model-path ./vicuna-7b > model_worker.log 2>&1 &
# nohup python -m fastchat.serve.gradio_web_server --host localhost --port 8000 > gradio_web_server.log 2>&1 &窗口一 | 指令一:

窗口二 | 指令二:
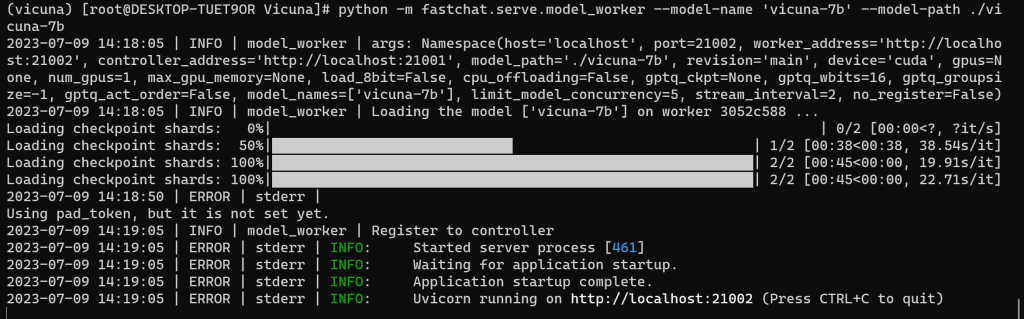
窗口三 | 指令三:

演示效果:
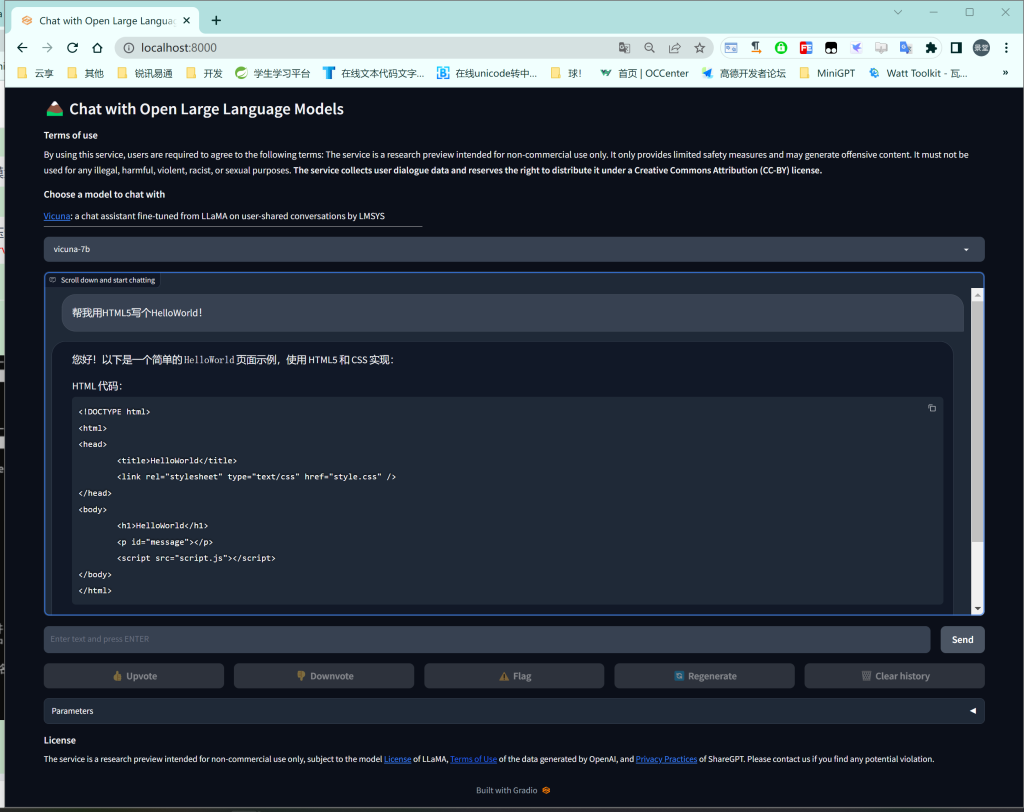
- 打赏



- 微信
- 支付宝